- Published on
How to ingest records from Cosmos DB using Spark
Table of Contents
Introduction
In this post, we’ll learn how we can ingest data from Cosmos DB using Spark’s structured streaming. We will use Databricks as the platform. If you don’t have a Databricks account you can use the community version.
Installing Cosmos DB Connector
Spark does not support cosmos db out of the box. So, in order to connect spark and cosmos, we need to install the cosmos db connector library.
First, go to this link and copy the latest maven coordinates for the library. These coordinates look something like this: com.azure.cosmos.spark:azure-cosmos-spark_3-3_2-12:4.19.0
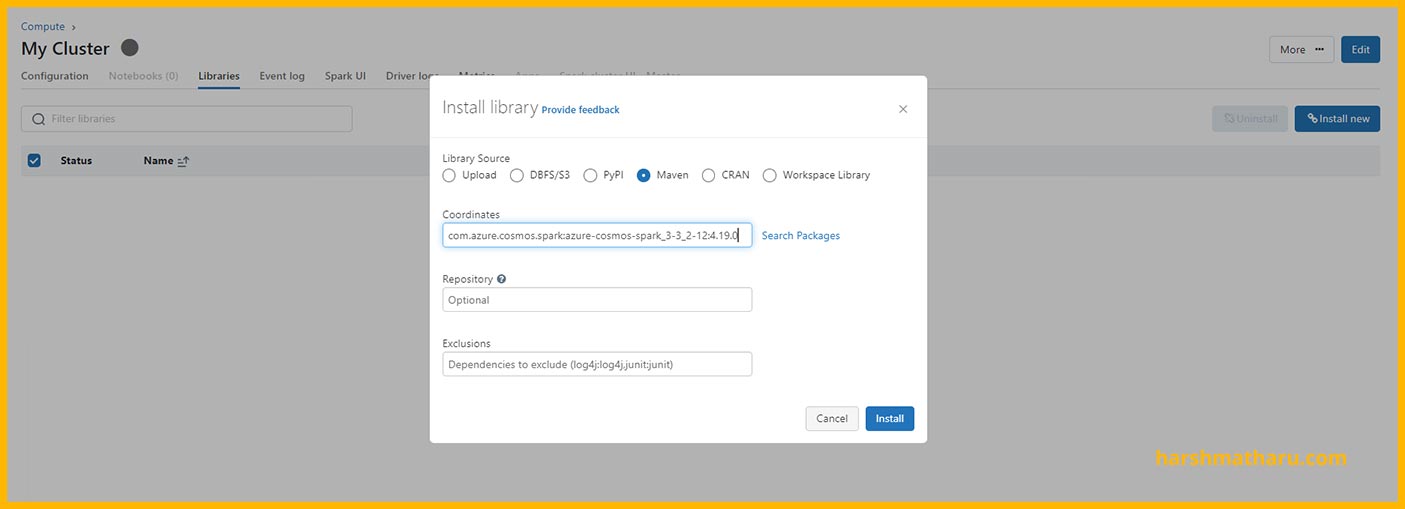
Then, in the Databricks workspace, open the Compute page and then open the cluster on which connector should to be installed. In the details page of that cluster, click on the Libraries tab and then click Install new button.
A popup will open, select the Maven option and then paste the copied maven coordinates and then click on install. After a few seconds the library would install.
Reading data from Cosmos DB
Create a notebook Ingestion with default language as python and add the following code cells in the notebook.
%sql
CREATE TABLE IF NOT EXISTS raw_records TBLPROPERTIES (delta.enableChangeDataFeed = true);
We have created a delta table for storing raw ingested data. Note the delta.enableChangeDataFeed = true, by enabling this property we have enabled Change Data Capture for this delta table. In the transformation step, we’ll read the CDC stream of this delta table and will perform the transformation.
read_cfg = {
"spark.cosmos.accountEndpoint": cosmos_endpoint,
"spark.cosmos.accountKey": cosmos_key,
"spark.cosmos.database": cosmos_db,
"spark.cosmos.container": cosmos_container,
"spark.cosmos.read.inferSchema.includeSystemProperties": "true",
"spark.cosmos.read.inferSchema.enabled": "false",
"spark.cosmos.changeFeed.startFrom": "Beginning",
"spark.cosmos.changeFeed.mode": "LatestVersion",
"spark.cosmos.changeFeed.itemCountPerTriggerHint": "100",
"spark.cosmos.read.maxItemCount": "100",
"spark.cosmos.read.partitioning.strategy": "Restrictive"
}
Next, we have defined the read configuration as a python dictionary. You can read about all the available configurations here
Some important ones are mentioned below:
Schema Inference
By default schema inference is enabled but we can use the below option to enable or disable it.
spark.cosmos.read.inferSchema.enabled: true
With schema inference enabled, spark will automatically guess the schema of the data by looking at some sample data. By default spark looks at the first 1000 rows of the container to infer the schema.
We can also adjust the sample size for schema inference using the option below. Default is 1000 records.
spark.cosmos.read.inferSchema.samplingSize: 1000
Also, we have another option to specify an exact query. When specified, spark will use this query to infer schema rather than getting the first n (sample size) records.
spark.cosmos.read.inferSchema.query: “SELECT * FROM r ORDER BY r.Date DESC”
We are not using schema inference, We will specify actual schema in the Transformation section. There are two reasons for that:
While ingesting data from source, we want the ingestion to be as fast as possible because we are reading data from our OLTP database and we don’t want to put it under load for an extended period of time. So we skip any transformations at this point and just ingest the raw data.
Schema inference is fine as long as our source schema is static. But if our source schema keeps on evolving then we could face some potential problems. Imagine if you have some field which is added at a later point in time and the inference sample does not contain it then it will be discarded.
We can use custom query inference for the cases mentioned in the second point.
When we disable schema inference then the schema of data returned by the stream changes and the data is present in serialized form in the _rawBody column.
Change Feed Configuration
When reading from the Change Feed of Cosmos we can start the stream from the beginning by specifying "spark.cosmos.changeFeed.startFrom": "Beginning" or we can ingest the current on-going changes by using the value Now instead of Beginning.
There is also one more value we can use i.e. any datetime value, for example 2021-07-21T16:10:15, if we want to start the stream from a specific date and time.
When a stream restarts, it will start from the checkpoint location rather than spark.cosmos.changeFeed.startFrom values. We’ll see the checkpoint location in the next section.
Partitioning Strategy
By default spark.cosmos.read.partitioning.strategy is set to Default and spark dynamically calculates the number of partitions required to ingest data.
We can set its value to Custom, then we can specify the number of partitions manually using spark.cosmos.partitioning.targetedCount configuration.
Or we can set spark.cosmos.read.partitioning.strategy to Restrictive. In this strategy, spark creates partitions equal to the number of physical partitions we have in our Cosmos DB.
If you face request throttling (429) while running spark then you can decrease the partition count or set the strategy to Restrictive. It will reduce the level of parallelism in spark thus reducing the rate at which requests are sent to Cosmos DB.
Now let’s move to ingestion.
There are two options available to us on how we can ingest data. Either we can batch read records or we can read the stream from the Change Feed.
We’ll go with reading from the Change Feed stream because:
When we are reading from the Change Feed, we don’t have to worry about updating already ingested records. All the updates are captured by the Change Feed and made available for consumption. The Change Feed in Cosmos DB continuously captures any modifications that occur in the monitored container, including inserts, updates, and deletes. This feature provides a reliable and efficient way to keep track of changes and process them in near real-time.
With streaming we don’t have to worry about manually checkpointing the state of the data ingested. Spark automatically handles the checkpointing process for us and whenever we restart the stream it knows from which point the stream should be started.
checkpoint_location = "/mnt/delta/record_ingestion/checkpoint"
(spark
.readStream
.format("cosmos.oltp.changeFeed")
.options(**read_cfg)
.load()
.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", checkpoint_location)
.option("mergeSchema", "true")
.toTable("raw_records"))
This is the code for reading the stream and then writing it to a table. The format should be cosmos.oltp.changeFeed. Also, note **read_cfg, we are using the unpack operator to pass all our configurations as named arguments.
While writing we are using the delta format. Output mode is set to append which means that we’ll only append new data and not overwrite or update. Checkpoint location is a path to any directory where we want to store the state of the stream. If the stream is stopped/canceled then it will resume from the point where it left off when its restarted again. The mergeSchema option ensures that any schema changes in the incoming data are merged with the existing schema in the Delta table.
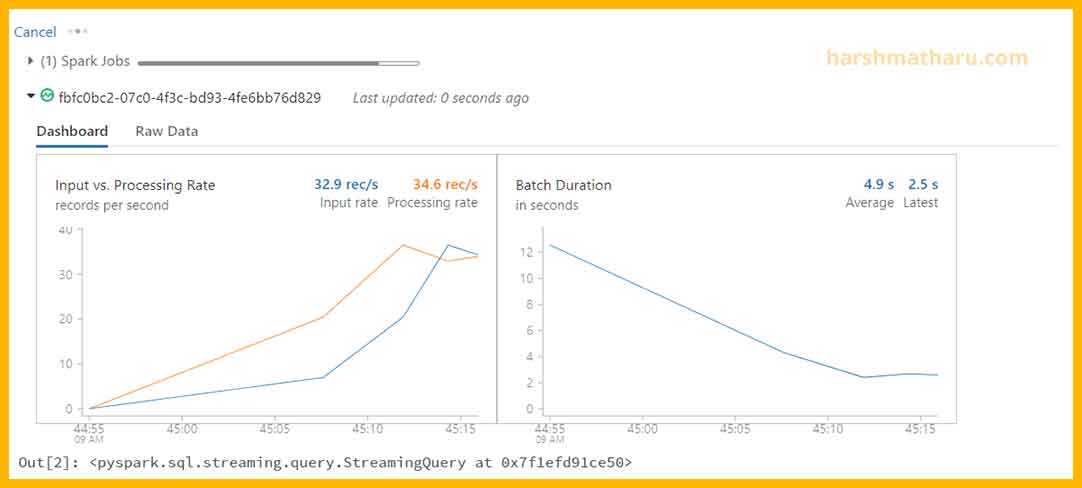
When you start the stream you will see the following graph output which shows the status of the stream. You can see the rate of ingestion as well as other things in the Raw Data tab.
Handling Data Transformation
In this section we’ll transform the ingested data and store it in a new table. Create notebook Transform with default language set to python and then add the following cells in the notebook.
Add the required imports.
from pyspark.sql.functions import from_json
from pyspark.sql.types import *
from delta.tables import *
Create the table where we will store the transformed data. Note that we have specified the id column because we are going to need it. and rest other columns will be added using auto-merge schema which we will enable next.
%sql
CREATE TABLE IF NOT EXISTS records (id STRING)
Now, define the schema for the record.
schema = (StructType()
.add("id", StringType(), False)
.add("partitionkey", StringType(), False)
.add("Age", IntegerType(), False)
.add("Name", StringType(), False))
Spark's structured streaming does not support upsert operation directly. Rather, for these types of cases, spark provides foreachBatch() method which takes a function as an argument and in this function we can define our custom persistence logic.
def process_batch(batch_df, batch_id):
target = DeltaTable.forName(spark, "records")
source = (batch_df
.select(from_json("_rawBody", schema).alias("value"))
.select("value.*"))
(target
.alias("t")
.merge(source.alias("s"), "t.id = s.id")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute())
We will use the foreachBatch() method because we want to perform an upsert operation and that is why we have defined this process_batch() function which is doing exactly that. It will receive two arguments, a batch of data as a dataframe and a unqiue id for the batch. Inside this function we are instantiating records table as dataframe (target) and transforming the received batch by first parsing the json stored in _rawBody column and then exploding each property of json as a column.
For example, a batch_df dataframe
| id | _rawBody |
|---|---|
| 123 | { "id": "123", "partitionkey": "123", "Age": 23, "Name": "Harsh" } |
is converted to this source dataframe
| id | partitionkey | Age | Name |
|---|---|---|---|
| 123 | 123 | 23 | Harsh |
After that we are performing the upsert operation by matching id in both dataframes.
Record from cosmos db is stored in _rawBody column in serialized json format.
Why are we using an upsert operation?
Since we are reading Change Feed, it will have multiple entries for each record. For example, if a record is inserted in the database and then it is updated twice then Change Feed will have 3 entries for the record (1 for insertion and 2 for updates). So we don't want to insert the record everytime, instead we will update the record if we encountered it more than once.
Next, enable the autoMerge. Since we are using update-and-merge operation, the .option("mergeSchema", "true") option is not supported here. So, we are using this way to enable schema merge.
spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", "true")
Now we are ready to create the transformation stream. In order to read the stream from the delta table we need to specify the readChangeFeed option.
The startingVersion specifies from which point to start the stream initially. You can think of this option as the same we used in cosmos options which was spark.cosmos.changeFeed.startFrom. The value 0 represents here that we want to read from beginning.
Also, note we are passing the process_batch function as an argument to foreachBatch() method.
(spark
.readStream
.format("delta")
.option("readChangeFeed", "true")
.option("startingVersion", 0)
.table("raw_records")
.writeStream
.foreachBatch(process_batch)
.option("checkpointLocation", "/mnt/delta/record_transformation/checkpoint")
.start())
If we want to run both notebooks parallelly by using Databricks workflows then we have to add a timeout before transform stream. Because if we start both streams at the same time, initially when the raw_records table is empty, then the transform stream will throw an exception. So by adding a timeout we are letting the raw_records table to be populated with at least one record and then our transform stream can start without any problem.
import time
time.sleep(30)
View RU consumption of Change Feed Requests
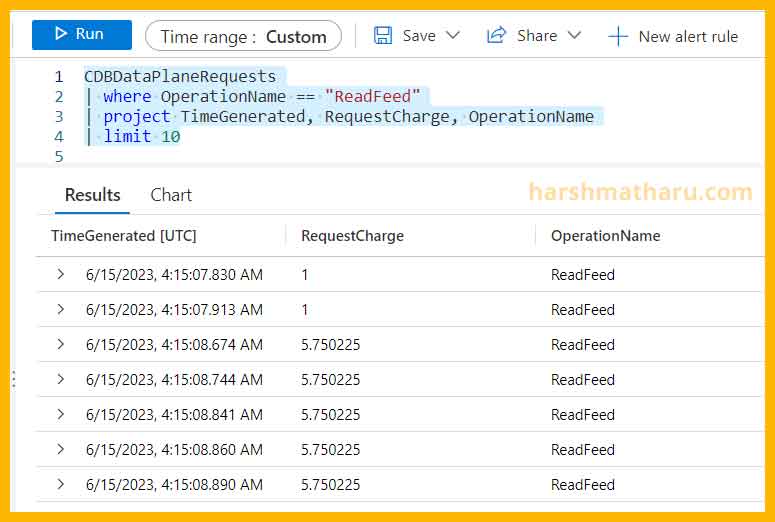
If you have not enabled logs from cosmos db, you can view this post and see how to enable it. Once enabled we can execute the following query in Log Analytics workspace to view how many RUs are being consumed by the Change Feed Read operations.
CDBDataPlaneRequests
| where OperationName == "ReadFeed"
| project TimeGenerated, RequestCharge, OperationName
| limit 10
Conclusion
In this blog post, we learned how to install the Cosmos DB connector for Spark and read data from Cosmos DB using the change feed. We covered the configuration options for reading data, including schema inference, change feed configuration, and partitioning strategy. Additionally, we discussed the process of handling data transformation and demonstrated how to perform upsert operations on the transformed data. By following these steps, we can effectively integrate Spark and Cosmos DB for real-time data processing and analysis.